%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Open Source Model

Camerabench
CameraBench is a model for analyzing camera motion in videos, aimed at understanding the motion patterns of cameras through video interpretation. Its main advantage lies in using generative visual language models for principle classification of camera motions and video-text retrieval. Compared with traditional Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM) methods, this model shows significant advantages in capturing scene semantics. The model is open-source and suitable for use by researchers and developers, with more improved versions to be released later.
Research Tools
39.7K
Hunyuanvideo I2V
HunyuanVideo-I2V is an open-source image-to-video generation model developed by Tencent based on the HunyuanVideo architecture. This model effectively integrates reference image information into the video generation process through image latent splicing technology, supports high-resolution video generation, and provides customizable LoRA effect training functions. This technology is of great significance in the field of video creation, helping creators quickly generate high-quality video content and improve creation efficiency.
Video Production
93.3K
Skyreels V1
SkyReels-V1 is an open-source, human-centric video foundation model fine-tuned on high-quality cinematic footage, specializing in high-quality video content generation. This model achieves top-tier performance in the open-source domain, rivaling commercial models. Key advantages include: high-quality facial expression capture, cinematic lighting and visual effects, and the efficient inference framework SkyReelsInfer, which supports multi-GPU parallel processing. This model is suitable for scenarios requiring high-quality video generation, such as film production and advertising creation.
Video Production
101.3K
Deepscaler 1.5B Preview
DeepScaleR-1.5B-Preview is a large language model optimized by reinforcement learning, dedicated to enhancing the capabilities of solving mathematical problems. It achieves significant improvements in accuracy within long-text inference scenarios, driven by distributed reinforcement learning algorithms. Key advantages include efficient training strategies, notable performance gains, and the flexibility of open-source availability. Developed by the Sky Computing Lab and Berkeley AI Research team at the University of California, Berkeley, this model aims to advance the application of artificial intelligence in education, especially in mathematics education and competitive mathematics. Available under the MIT open-source license, it is completely free for researchers and developers to use.
Education
78.7K
Lumina Video
Lumina-Video is a video generation model developed by the Alpha-VLLM team, primarily designed to produce high-quality video content from text prompts. This model leverages deep learning technology to generate corresponding videos based on user-input text, offering efficiency and flexibility. It holds significant importance in the video generation field, providing powerful tools for content creators to quickly generate video materials. The project is currently open-source, supporting various resolutions and frame rates, and includes detailed installation and usage guidelines.
Video Production
69.8K
Zonos V0.1
Zonos-v0.1 is a real-time text-to-speech (TTS) model developed by the Zyphra team, equipped with high-fidelity voice cloning features. This model includes a 1.6B parameter transformer model and a 1.6B parameter hybrid model, both released under the Apache 2.0 open source license. It can generate natural and expressive speech from text prompts and supports multiple languages. Additionally, Zonos-v0.1 enables high-quality voice cloning from 5 to 30-second voice clips and can be adjusted based on speaking speed, pitch, quality, and emotion. Its key advantages include high generation quality, support for real-time interaction, and flexible voice control capabilities. The release of this model aims to advance research and development in TTS technology.
Speech-to-Text
197.3K
BEN2
BEN2 (Background Erase Network) is an innovative image segmentation model that employs the Confidence Guided Matting (CGM) process. It utilizes a refinement network specifically designed to handle pixels with lower model confidence, achieving more precise cut-out effects. BEN2 excels in hair segmentation, 4K image processing, object segmentation, and edge refinement. Its base model is open-source, allowing users to try the complete model for free via API or web demonstration. The model's training data includes the DIS5k dataset and a 22K proprietary segmentation dataset, meeting various image processing needs.
Image Editing
58.5K
Llasa 3B
Llasa-3B is a powerful text-to-speech (TTS) model developed based on the LLaMA architecture, focused on Chinese and English speech synthesis. By integrating XCodec2's speech encoding technology, it efficiently converts text into natural and fluent speech. Its main advantages include high-quality speech output, support for multilingual synthesis, and flexible speech prompting capabilities. This model is suitable for various applications requiring speech synthesis, such as audiobook production and voice assistant development. Its open-source nature also allows developers to explore and expand its functionalities freely.
Text to Speech
104.6K
Minirag
MiniRAG is a retrieval-augmented generation system designed for small language models, aimed at simplifying RAG processes and enhancing efficiency. It addresses the performance limitations of small models within traditional RAG frameworks through a semantically aware heterogeneous graph indexing mechanism and lightweight topological enhanced retrieval methods. This model shows significant advantages in resource-constrained scenarios, such as on mobile devices or edge computing environments. Its open-source nature allows for easy adoption and improvement within the developer community.
Model Training and Deployment
56.9K
Llama 3 Patronus Lynx 8B Instruct
Llama-3-Patronus-Lynx-8B-Instruct is a fine-tuned version of the meta-llama/Meta-Llama-3-8B-Instruct model developed by Patronus AI, primarily designed to detect hallucinations in retrieval-augmented generation (RAG) settings. The model is trained on multiple datasets, including CovidQA, PubmedQA, DROP, and RAGTruth, featuring both human-annotated and synthetic data. It evaluates whether a given document, question, and answer are faithful to the document content, refraining from providing new information outside the document or contradicting it.
Model Training and Deployment
46.4K
Meta Video Seal
Meta Video Seal is an advanced open-source video watermarking model capable of embedding enduring, invisible watermarks even after video editing. With the increase of AI-generated content, verifying video sources has become critical. Video Seal ensures the integrity of watermarks by embedding invisible watermarks, which is essential for copyright protection and content validation.
Video Editing
51.1K
Olmo 2 1124 13B Instruct
OLMo-2-1124-13B-Instruct is a large language model developed by the Allen AI Institute, focusing on text generation and dialogue tasks. The model excels in various tasks, including solving mathematical and scientific problems. It is based on a 13B parameter architecture, refined through supervised fine-tuning on specific datasets and reinforcement learning to enhance its performance and safety. As an open-source model, it allows researchers and developers to explore and improve upon language modeling science.
Chatbot
45.3K
Llama 3.1 Tulu 3 70B
Llama-3.1-Tulu-3-70B is part of the Tülu3 model family, offering comprehensive guidance for modern post-training techniques. The model excels not only in conversational tasks but also demonstrates outstanding performance in various tasks such as MATH, GSM8K, and IFEval. As an open-source model, it allows researchers and developers to access and utilize its data and code, advancing the field of natural language processing.
Text Generation
46.1K
Qwen2.5 Coder 1.5B Instruct GPTQ Int4
Qwen2.5-Coder is the latest series from the Qwen large language model, focusing on code generation, reasoning, and debugging. Built upon the powerful Qwen2.5 framework, this model has been trained on 550 trillion source code, text-code correlations, and synthesized data, making it one of the leading open-source code language models today, rivaling GPT-4 in coding ability. Additionally, Qwen2.5-Coder offers comprehensive real-world application capabilities, such as code agents, enhancing coding proficiency while maintaining strengths in mathematical and general skills.
Code Reasoning
44.7K
Qwen2.5 Coder 1.5B Instruct AWQ
Qwen2.5-Coder is the latest series of the Qwen large language model, designed for code generation, reasoning, and fixing. Built on the powerful Qwen2.5, this model has been trained on 550 trillion source codes, text code foundations, and synthetic data, elevating its coding capabilities to the forefront of open-source code LLMs. It not only enhances coding abilities but also maintains strengths in mathematics and general capabilities.
Code Reasoning
44.4K
Qwen2.5 Coder 3B Instruct GPTQ Int8
The Qwen2.5-Coder-3B-Instruct-GPTQ-Int8 is a large language model optimized for code generation, reasoning, and debugging, part of the Qwen2.5-Coder series. Based on Qwen2.5, it has been trained on a dataset including source code, code-text associations, and synthetic data, achieving 550 trillion training tokens. The Qwen2.5-Coder-32B has emerged as the leading open-source large language model for code, matching coding capabilities with GPT-4o. This model also provides a comprehensive foundation for real-world applications such as code assistance, augmenting coding capabilities while maintaining strengths in mathematics and general skills.
Code Reasoning
43.9K
Qwen2.5 Coder 3B Instruct GGUF
Qwen2.5-Coder is the latest series of the Qwen large language models, focusing on code generation, reasoning, and repair. Built on the powerful Qwen2.5, it has been trained on a dataset of 550 trillion tokens including source code, code-grounded texts, and synthetic data. Qwen2.5-Coder-32B has emerged as the most advanced open-source code large language model, matching the coding capabilities of GPT-4o. In practical applications, it provides a more comprehensive foundation, such as a code agent, enhancing coding prowess while retaining advantages in math and general abilities.
Code Reasoning
46.4K
Qwen2.5 Coder 32B Instruct GPTQ Int8
Qwen2.5-Coder-32B-Instruct-GPTQ-Int8 is a large language model specifically optimized for code generation within the Qwen series, featuring 3.2 billion parameters and supporting long text processing. It is one of the most advanced models in the field of open-source code generation. The model has been further trained and optimized based on Qwen2.5, showing significant improvements in code generation, inference, and debugging, while also maintaining strengths in mathematics and general capabilities. It utilizes GPTQ 8-bit quantization technology to reduce model size and enhance operational efficiency.
Long Text Processing
47.5K
Qwen2.5 Coder 1.5B Instruct
Qwen2.5-Coder is the latest series in the Qwen large language model family, focusing on code generation, code reasoning, and code fixing. Leveraging the powerful capabilities of Qwen2.5, the model was trained on 55 trillion source code, textual code bases, synthetic data, and more, making it a leader among open-source code generation language models, comparable in coding ability to GPT-4o. It not only enhances coding capability but also retains strengths in mathematics and general skills, providing a robust foundation for practical applications such as code agents.
Coding Assistant
48.6K
Qwen2.5 Coder 3B Instruct
Qwen2.5-Coder is the latest series of the Qwen large language model, focused on code generation, reasoning, and repair. Based on the powerful Qwen2.5, this model series significantly enhances code generation, reasoning, and repair capabilities by increasing training tokens to 5.5 trillion, including source code, text grounding, synthetic data, and more. The Qwen2.5-Coder-3B model contains 3.09B parameters, 36 layers, 16 attention heads (Q), and 2 attention heads (KV), with a total context length of 32,768 tokens. It stands out among open-source code LLMs, matching the coding capabilities of GPT-4o, and provides developers with a powerful code assistance tool.
Coding Assistant
46.1K
Cogvideox1.5 5B SAT
CogVideoX1.5-5B-SAT is an open-source video generation model developed by the Knowledge Engineering and Data Mining team at Tsinghua University. It is an upgraded version of the CogVideoX model, supporting the generation of 10-second videos as well as videos in higher resolutions. The model includes modules such as Transformer, VAE, and Text Encoder, enabling video content generation based on textual descriptions. With its powerful video generation capabilities and high-resolution support, the CogVideoX1.5-5B-SAT model provides a robust tool for video content creators, with broad application prospects in education, entertainment, and commercial fields.
Video Production
70.4K
Mochi In ComfyUI
Mochi is the latest open-source video generation model launched by Genmo, optimized for ComfyUI to operate effectively even on consumer-grade GPUs. Renowned for its high fidelity animation and excellent prompt adherence, Mochi brings state-of-the-art video generation capabilities to the ComfyUI community. Released under the Apache 2.0 license, this allows developers and creators to freely use, modify, and integrate Mochi without restrictive licensing issues. Mochi can run on consumer-grade GPUs such as the 4090 and supports multiple attention backends in ComfyUI, making it adaptable for VRAM less than 24GB.
Video Production
52.2K
Allegro
Allegro is an advanced text-to-video model developed by Rhymes AI, capable of converting simple text prompts into high-quality short video clips. Its open-source nature makes Allegro a powerful tool for creators, developers, and researchers in the field of AI video generation. Key advantages of Allegro include its open-source accessibility, diverse content creation capabilities, high-quality output, and compact yet efficient model size. It supports various precisions (FP32, BF16, FP16), with GPU memory usage at 9.3 GB in BF16 mode and a context length of 79.2k, equivalent to 88 frames. The technical core of Allegro includes large-scale video data processing, compressing video into visual tokens, and an expanded video diffusion transformer.
Video Production
72.3K
Lightrag
LightRAG is a retrieval-augmented generation model designed to enhance performance in text generation tasks by combining the strengths of retrieval and generation. The model delivers more accurate and relevant information while maintaining generation speed, which is especially crucial for applications requiring quick and precise information retrieval. The development of LightRAG stems from the need for improvements over existing text generation models, particularly in scenarios involving large datasets and complex queries. Currently, it is open-source and freely available, providing researchers and developers with a powerful tool to explore and implement retrieval-based text generation tasks.
AI text generation
56.9K
Fresh Picks
Cogview3 Plus 3B
Developed by a team from Tsinghua University, this open-source text-to-image generation model has broad application prospects in the field of image generation, featuring high-resolution output among other advantages.
AI image generation
66.8K
Fresh Picks
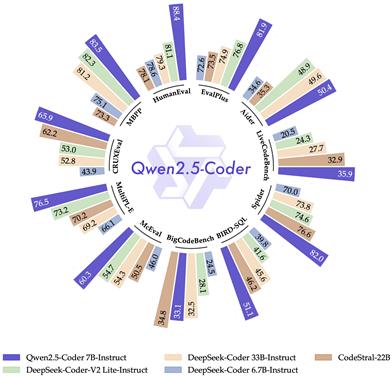
Qwen2.5 Coder
Qwen2.5-Coder is part of the Qwen2.5 open-source family, focusing on tasks like code generation, inference, and repair. By leveraging large-scale code training data, it improves code capability while maintaining mathematical and general skills. The model supports 92 programming languages and has shown significant advancements in code-related tasks. Qwen2.5-Coder is licensed under Apache 2.0 to accelerate the application of coding intelligence.
AI Code Assistant
60.7K

Qwen2.5
Qwen2.5 is a series of novel language models built on the Qwen2 language model, which includes a general language model Qwen2.5, as well as specialized models aimed at programming (Qwen2.5-Coder) and mathematics (Qwen2.5-Math). These models have been pre-trained on extensive datasets, demonstrating robust knowledge comprehension and multilingual support, making them suitable for various complex natural language processing tasks. Their primary advantages include higher knowledge density, enhanced programming and mathematical capabilities, and better understanding of long texts and structured data. The release of Qwen2.5 marks a significant advancement in the open-source community, providing developers and researchers with powerful tools to drive research and development in the field of artificial intelligence.
AI Model
58.5K
Auraflow V0.3
AuraFlow v0.3 is a completely open-source flow-based text-to-image generation model. Compared to the previous version, AuraFlow-v0.2, this model has undergone more computational training and fine-tuning on aesthetic datasets. It supports a variety of aspect ratios with width and height up to 1536 pixels. The model has achieved state-of-the-art results on GenEval and is currently in beta testing, constantly improving with community feedback being crucial.
AI image generation
80.0K
Fresh Picks
Cogvideox 2B
CogVideoX-2B is an open-source video generation model developed by the team at Tsinghua University. It supports video generation using English text prompts and requires 36GB of GPU memory for inference. The model can create videos that are 6 seconds long, with a frame rate of 8 frames per second, and a resolution of 720x480. It utilizes sinusoidal positional embeddings and currently does not support quantized inference or multi-GPU inference. Deployed using Hugging Face's diffusers library, it generates highly creative and application-oriented videos based on text prompts.
AI video generation
86.9K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M